말도 많고 탈도 많았던 Qt 4.2가 드디어 나왔다. 가장 큰 차이점은 http://doc.trolltech.com/4.2/qt4-2-intro.html 페이지에 그대로 나와 있다. Qt 4.2 덕분에 QOM에서 해결하지 못했던 난제 중 하나인 사용자 정의 온라인 사전 찾기 기능(기본적으로 뇌입어, 위키낱말사전 제공 예정), 시스템 트레이 상주(쓸 사람 있으려나) 등의 구현이 쉬워졌지만, 트롤텍이 말씀하시길 이 모든 기능을 저 골로 보낼 수 있는
가 등장하였다. CSS를 모르는 사람은 없을 것이다. 그런데 그런 CSS가 웹에만 쓰이는 것이 아니라 데스크탑 테마를 꾸미는 데 사용된다고?! 그것도 우리가 늘상 보아 오는 그런 것들에?! 나도 처음에는 이 개념이 잘 이해가 가지 않았지만, 위젯 스타일 시트 문서를 보니까 조금씩 이해가 가기 시작했다. 우선 간단한 예제를 보자.
이 예제는 Qt 4.2에 포함되어 있는 스타일시트 예제이다. 일단 이것을 기본값으로 실행시키면 평범한 윈도 프로그램인 척 하고 있다.
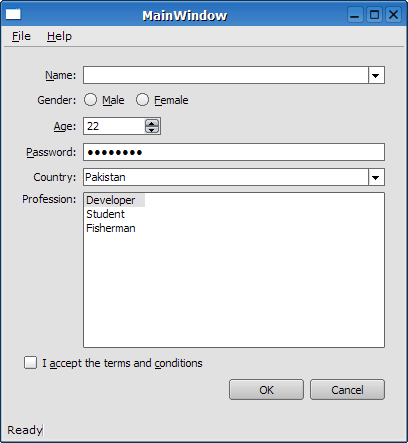
Coffee 스타일시트를 적용시키면 이렇게 변신한다.
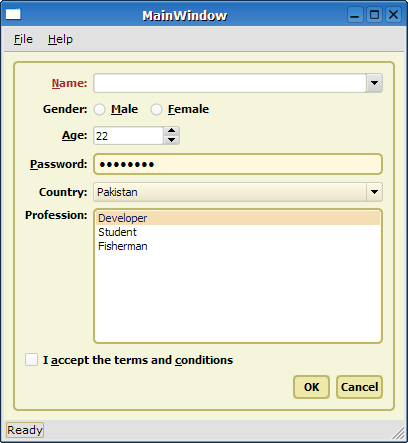
Pagefold 스타일시트는 이렇게 변하는데, 우리가 주목해야 할 것은 엄마친구아들이 아닌, QWidget에 걸려 있는 백그라운드이다. 즉, 다른 클래스에도 스타일시트를 적용하면 간지나는 버튼을 만들기 위해서 고민해야 할 필요가 없다는 것이다.
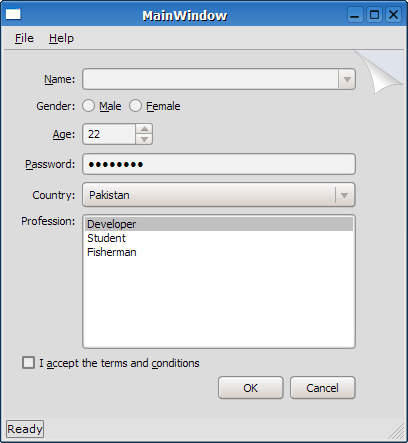
KDE4가 아마도 Qt 4.2 기반으로 탄생할 것이라고 하는데, 이렇게 되면 테마 만들기가 더욱 수월해 질 것이라고 하며, 위젯들의 OpenGL 기반 렌더링까지 지원하기 때문에 별의별 일이 가능해질 것이라고 한다. 일단 QOM에도 스타일시트 기반 스킨 기능을 추가시키는 것이 좋을 것 같은데… 아직 QOM 2가 끝나지 않은 상태에서 섣부른 기댄가.
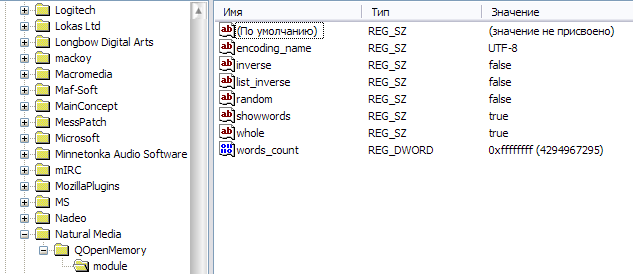 리눅스의 경우 conf 파일이 비슷하게 생긴다고 알고 있으며, 결론은 귀찮게 레지 값이나 텍스트 파일 찌르는 것보다 이런 게 더 낫다는 것이다.
리눅스의 경우 conf 파일이 비슷하게 생긴다고 알고 있으며, 결론은 귀찮게 레지 값이나 텍스트 파일 찌르는 것보다 이런 게 더 낫다는 것이다.